蚂蚁金服技术团队
分类: 数据库开发技术
2019-11-20 09:02:19
2019双11,支付宝参战的第十一年。
与十一年前相比,双11的许多东西都改变了。比如金额——2684亿,差不多是十一年前的5000倍;比如流量——订单峰值54.4万笔/秒,曾经是想都不敢想的数字;再比如层出不穷的新技术,就是这些惊人数字背后的“秘密武器”,给迎战双11的战士们作最完备的武装。

也有始终不变的东西。大战来临前的紧张、不安、如履薄冰,对每一个细节反复check的“强迫症”,以及胜利之后的欣喜、释然、满心充实,和下一步砥砺前行。
支付宝的技术工作,就是“半年搞建设,半年搞大促”。虽然是一句戏言,但足够从侧面证明大促作为实践战场的重要性。而每当双11圆满落下帷幕,技术人也就到了收获的季节。那些历经双11大考的新技术,就像经历过了“成人式”一样,一一走到台前开始独当一面。
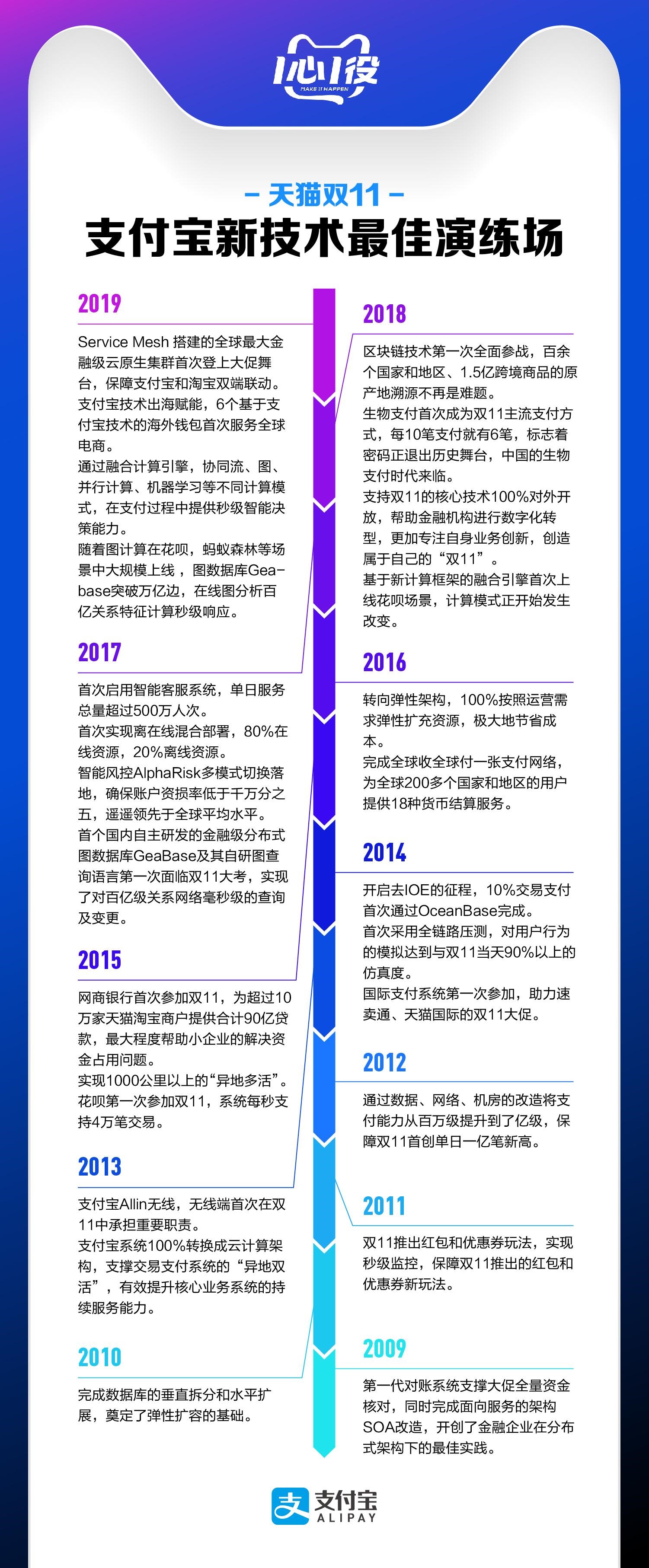
众所周知,金融机构因为肩负的责任重大,面对新技术时,普遍都是比较保守的。支付宝也不例外,尤其是在双11这种场景下,流量大,峰值高,平时不管多小的问题,在这时候都可能被放大成不得了的大问题。
于是,今年的大促迫在眉睫时,SOFAMesh团队还在纠结。来自周围的各种声音,让他们感到压力很大。被问到的最多的问题,就是“这个靠不靠谱?”
一个“行”字,在双11的面前,可能有千钧之重。能不能扛过零点的流量峰值?能不能保障稳定?能不能保证不出差错?
Mesh是一项很新的技术,社区开源项目本就不成熟,而SOFAMesh是支付宝从第一行代码开始完全自主开发的项目,在金融级的严苛要求面前,在双11的极端场景之下,究竟行不行?谁心里都没有底。
然而此时不上,整整两年的心血就白费了。反过来说,如果能打赢这一仗,就证明云原生之路在双11这种体量的考验之下都是可行的,这对于整个行业而言,会是一个很好的标杆。
“蚂蚁金服要做金融行业技术的拓荒者和实践者。”资深技术专家杨海悌说。
这已不是蚂蚁金服第一次做“吃螃蟹的人”,在金融机构普遍依赖IOE时,他们率先开始探索分布式,现在分布式渐渐成为主流,他们又率先琢磨起云原生。
“以前都是业务推动技术,现在到了技术为业务提供红利的时候了。”对于自己看着长大的SOFAMesh,杨海悌一面很有信心,一面也十分忐忑。
SOFAMesh是支付宝针对金融行业的特殊需求而开发的金融级中间件,属于金融级云原生分布式框架SOFAStack的一部分,这个框架的开发始于2009年,几乎和双11同龄。
是骡子是马,总得遛过了才知道。SOFAMesh的第一份答卷很快交了出来——以往分时复用的资源切换需要4小时,用上了SOFAMesh之后,不到4分钟。性能提升将近百倍。
分时复用,顾名思义,就是在不同的时间段里让同一个资源能够“复用”于多个应用。这一技术能够减少资源闲置,提高资源的利用效率。这一技术在2018年双11就曾立过功——当时,支付宝面对这天猫双11和自己的会员大促的“双大促”挑战,为了节约成本少采购一些资源,上线了分时调度1.0,使用同一批资源同时支持两个大促,在支撑天猫双 11 和经济体用户增长两个大促的同时,IT成本一分钱也没有涨。
但去年在弹性架构模式下做分时调度,切换资源需要重新配置和部署相关系统,4个小时的切换时间,虽然成功支持了“双大促”,还是满足不了对短时间内快速调用资源有需求的业务。
到了今年,由于SOFAMesh的上线,切换资源不再需要重新部署,切换时间缩短到了3分40秒。这意味着,像蚂蚁森林那样每天都会面临流量小高峰的业务,无需事先留足资源余量,提前10分钟开始切换资源,都绰绰有余。
“将来,切换时间还有望缩短到秒级。”杨海悌说。
2019年双11,SOFAMesh扮演了非常重要角色——100%覆盖蚂蚁金服核心支付链路,几十万容器,峰值千万QPS,平均RT(响应时间) 0.2ms,是业界最大的 Service Mesh 集群。它在洪峰面前的稳定性和平滑性,以及对效率的显著提升,都是有目共睹的。

这张漂亮的成绩单背后,其实就是一个字——行。
“云原生”已经成为业界公认的技术趋势,它的目标是提升运维效率、降低资源使用成本、提升服务安全可靠性等。云原生带来的基础设施升级,为技术演进提供基础能力支撑,并且提升未来架构空间的想象力。2019也是支付宝的金融级云原生落地元年,包括SOFAMesh在内的一系列云原生技术,经历双11的考验之后,向整个业界证明——我们行,云原生这条路,也行。
双11之后,蚂蚁金服举办的发布会上,副CTO胡喜宣布,会将打磨十年之久的SoFAStack对外公开。
正如“元年”一词所说,这只是蚂蚁金服在新的开拓之路上迈出的第一步。
OceanBase被人质疑“行不行”的次数,更是多到数不过来。
数据库是命脉,尤其是金融机构的数据库,出一点问题都是真金白银的问题,哪个业务都不敢冒风险,老老实实抱着老牌进口货Oracle,图个太平。
但Oracle也没见过双11这种阵仗,随着双11的流量连年翻番,它的性能眼见着碰到了天花板。2014年双11前的压测,Oracle出现了10%的流量缺口。

OceanBase感到机会来了。在那之前,他们已经“蛰伏”了四五年,没有固定的业务,最落魄的时候,甚至面临团队解散和项目取消的境况。
当时的OcaenBase将满5岁,版本号却还是0.x,外表看来甚至还是个demo,一上来就要承接双11的10%的流量,相当于支付宝平日流量的最高峰,而且要做的还是最核心的交易系统——一分钱都不能出错的那种。
一时之间,“你们行不行”的质疑声此起彼伏。
“别人说我们不行的时候,我们都非常坚定地认为,行。”蚂蚁金服研究员杨传辉说。他是OceanBase开发团队的初期成员之一,亲眼见过OceanBase写下第一行代码。
从拿下10%的任务,到双11的正式大考,时间不足两周。最后十来天,资深运维专家师文汇带着全团队几乎不眠不休地做优化,硬是把长达10毫秒的响应时间降低到了1毫秒以下。
那一年的双11,OceanBase没出一个差错,一战成名。
今年的双11,OceanBase的版本号是2.2。在为版本命名方面,他们的谨慎作风一如既往。
但是OceanBase的每一次版本迭代,发生的都是“脱胎换骨”的变化,自己创下的纪录,也由自己不断刷新——
2018年双11,基于OceanBase 2.0分区方案的架构正式上线,这一架构解决了数据库可扩展的瓶颈,将每秒交易的承载能力提升到百万级,并让性能提升了50%。
50%的提升不是个小数目,但更令人惊讶的是,仅仅一年之隔,在2019年的双11中,全新上线的OceanBase2.2版本,在2.0的基础上,又让性能提高了50%。
就在今年的10月3日,权威机构国际事务处理性能委员会TPC披露:蚂蚁金服的分布式关系数据库OceanBase,打破美国甲骨文公司保持了9年的世界纪录,登顶TPC-C榜单,同时也成为首个登上该榜单的中国数据库系统。
短短的一个月之后,在2019年双11的考场之上,OceanBase2.2又再次刷新了数据库处理峰值,达6100万次/秒,创造了新的世界纪录。
在金融级核心数据库的严格要求之下,OceanBase为何还能有这样跨越式的性能升级?
关键的秘密在于,OceanBase背后是原生的分布式数据库设计以及PAXOS协议,通过水平扩展x86服务器就可以达到无限伸缩,支持大规模高并发的效果。
另一方面,今年为了进一步提升性能和降低延迟,OceanBase还通过中间件的优化,自动将多条SQL聚合成轻量级的存储过程,这个过程让原本需要数十次SQL网络交互的任务降低为单次网络交互,整体RT降低了20%。
现在,支付宝的业务已经100%跑在OceanBase上,作为我国第一个自研的金融级分布式数据库,经过六年的双11锤炼,它也已经具备了走出蚂蚁金服、走向更广阔天地的底气。
今年双11中,支付宝支付业务100%切换到OceanBase内置的Oracle兼容模式上,支持Oracle语法以及存储过程优化的同时,又兼具OceanBase的分布式能力,如分布式分区表、全局事务等,响应时间也更加平稳。双11之后,OceanBase2.2也将正式公开发布。
“不过,在别人觉得我们什么都行的时候,我们反而会冷静下来,想想自己还有哪些不行的地方。”杨传辉说,对技术上一切未知的敬畏,才能让大家走得更远。
“过去很长一段时间图数据库和图计算一直停留在学术研究阶段,行业应用场景不多,是因为没有强的场景驱动,所以市场没有太多发展”, 蚂蚁金服计算存储首席架构师何昌华指出。但是反过来看,图相关的产品近年来热度不断攀升,其核心原因是因为强场景的驱动,特别是金融场景,它非常善于处理大量的、复杂的、关联的、多变的网状数据,通过节点和关联的数据模型去快速解决复杂的关系问题。
蚂蚁的一站式图平台的诞生,也有着鲜明的蚂蚁金服特色,同样是“被业务倒逼出来的”。
蚂蚁金服在2014年左右就开始跟进社区的图计算的研究,当时的团队在一些开源产品基础上进行了小规模的尝试,做了之后发现效果很好,图数据库能够很好地和金融、社交业务结合起来。但是,蚂蚁金服有着巨大的数据量,需要以分布式架构来支撑高并发的大数据量和大吞吐量,但当时无论是开源还是商业数据库产品都只是单机版,都难以适应蚂蚁金服如此大的数据量和复杂的环境。于是,艰难而又步步扎实的自研之路开始了。
最开始,要解决的是图数据的存储和在线查询的问题。
从数据量来看,分布式架构是唯一的选择。从满足金融场景高并发低延时的需求来看,选择原生图结构而非基于关系型数据库基础上封装图数据,成为必然。但也因为以上两点,导致整个开发难度大大增加。
从2015年初团队开始组建,经过“冬练三九、夏练三伏”的苦修,以及在代码、运维、稳定性等每一环节的极致追求,第一个图数据库版本GeaBase在2016年初发布。
而这时候,刚好遇到支付宝史上最大一次改版,模块化功能被替换成信息流,大大强化了社交关系属性,GeaBase开始接入支付宝链路。
百炼成钢,经过几个月的压测,2016年6月,新版支付宝上线,GeaBase迎来了第一笔流量。接着几年,从支付宝大改版到新春红包再到双11,GeaBase迎来了业务的绽放期,到2019年双11,GeaBase双11主链路上单集群规模突破万亿边,点边查询突破800万QPS,平均时延小于10ms;成为支付宝核心链路上非常重要的一环;
数据存储和查询的问题解决了,紧接着要解决的是分析计算的问题。

在一开始,我们思考的是如何在海量的图数据里做数据挖掘的问题。在面对千亿乃至万亿级规模,几TB到几百TB的数据,用超大内存物理机和高速网络来实现离线全图计算,对企业来说不太现实,资源也存在极大的浪费。因此,我们重点放在如何在满足业务功能/性能需求的同时,利用碎片化的现有资源,实现 “按需计算”的能力。
因此,2017年,我们在海量数据基础上,设计了一套离线计算的框架,提供自适应的分区策略,资源消耗能比同类产品降低一个数量级,同时性能还能远远优于GraphX等开源产品。
同时,为了方便业务算法人员根据其业务进行二次开发,还开放了C++和JAVA的接口,除了业界常见的图编程框架的Pregel、GAS,我们还做了一定的“微创新”和能力扩展,提供了更高性能,更加丰富功能的接口。
全量分析计算的事情解决了,但随着“310”策略的推进,风控业务的发展,对分析的时效性的要求越来越高,分析需要更快,更实时,2018年,我们开始考虑在线图计算的能力。
有时候,并不是所有业务都需要进行复杂的图分析,而是在满足一定的条件后才开始进行子图的迭代计算。最后,基于图的迭代计算的结果,在进行数据链路的处理后再提供给在线使用。
因此,一个场景在完整的计算链路中,需要流计算和图计算两种模态的融合计算。我们打破了传统计算模态的边界,提供流图融合的计算系统。通过将数据流和控制流相结合,并提供动态DAG的能力,从而实现按需计算,弹性扩缩容。
用户可以通过一套统一的DSL(SQL+Gremlin/GQL)、一套计算系统来实现完成流图融合的链路,实现基于数据驱动的在线图计算能力,同时,减少了用户的学习、运维成本。
在2019年双11上,在线图计算技术大放异彩,通过秒级决策,在花呗等场景帮助业务效果提升12倍。
从“海量”图存储,到离线全图 “按需计算”,再到“实时”在线图计算,蚂蚁的图智能技术跟随业务一步步发展,壮大。
今年的双11还落地应用了一套新的“神器”——融合计算引擎,它耗费了近百位工程师一整年的心血。
融合计算引擎的基础,是蚂蚁金服联合 UC Berkeley 大学推进的新一代计算引擎Ray,它很年轻,2018年融合计算引擎项目启动时,它只有几万行代码,距离金融级线上环境的应用还差得很远。
“我们用了一整年,把它增加到了几十万行代码,并且涵盖了C++、java、Python等所有语言。”蚂蚁金服资深技术专家周家英说。
至少4个团队在共同“养育”这个引擎,四个奶爸带娃,磕磕绊绊,在所难免,难度远远大于一个团队负责一个引擎。
但开发时的“难”,是为了应用时的“简”。
在计算引擎执行层面,不同计算模式的数据是可以在引擎内共享的,很少借助第三方存储,因此对外部存储和网络传输的开销也都有极大的节省。
在应用方面,融合计算引擎不仅能够解决金融场景中需要衔接多个不同计算模式的难题,还能支持各种不同时效性的业务,并在支付过程中提供秒级智能决策能力。
并且随着融合引擎的落地,也改变着技术同学的研发习惯。我们希望通过融合计算引擎,达成研发态,运行态,运维态三位一体的统一:例如在动态图计算场景,计算开发同学只需要编写一个流+图的计算作业,就可以实现秒级6度邻居的图迭代计算;同样在机器学习领域,通过编写一个包含流+模型训练+服务的计算作业,就可以实现端到端秒级模型导出的在线学习能力。这样从研发到运行态,计算整体效率都得到了极大提升。
2018年,融合计算就在花呗反套现的智能甄别之中表现卓越。到了2019年,融合计算引擎已经在支付宝不同场景中落地——图计算在花呗,蚂蚁森林等场景中大规模上线,图数据库Geabase突破万亿边。
2019年支付宝新春红包活动中,融合计算引擎用在线学习能力支持了新春红包的智能文案,让它的算法跑在了新的在线学习的体系上。这个体系融合了流计算和机器学习,让机器学习的模型迭代速度从以前的小时级别,提升到了现在的秒级别。本次双11时,它在“支日历”的推荐算法方面发挥了重要作用。
通过融合流计算、服务和并发查询,融合计算引擎减少了60%的机器资源使用,把端到端的延迟压低到了毫秒级,同时还能支持金融网络的业务查询和监控。
今年双11中,融合计算引擎在至少三个场景中成功落地并被验证可行,“还跑在了蚂蚁金融级关键决策链路上。”周家英不无兴奋,“这证明了我们的计算引擎具备了金融级的能力。”
事实上,无论是在双11这样的极端大考场景中,还是在支付宝、阿里巴巴,以及各个互联网科技公司的日常应用场景中,数据驱动的业务也越来越多。相应地,海量数据的实时处理、分析和应用,以及人工智能、深度学习等新技术的开发,都在要求着更强大的计算能力,以及能够应对复杂场景的多种计算模式。
面对未来,更多的是未知——我们尚且不知未来会出现什么样的场景,这些场景会要求什么样的计算模式和计算能力。“融合计算是真正意义上的新计算的第一步。”蚂蚁金服计算存储首席架构师何昌华说。

