分类: 嵌入式
2018-08-07 14:38:28
短距离通信方法很多,有NFC、二维码、蓝牙等,它们各有各自的特点和限制。比如NFC和蓝牙需要硬件支持,二维码是一个伟大的发明,解决了很多问题,但是前提是信息接收的一方需要有图像采集单元。声波通信是利用发送端播放包含了信息的音频,接收端对音频进行采集,分析出发送的数据来进行通信。所以也有一个限制就是接收端和发送端得有音频输入和音频输出的单元(这是显而易见的)。目前声波通信的方案有很多,比如支付宝咻咻咻等,而根据方案的不同还有其他方面的限制,比如采样率、性能消耗和自动增益单元等。
由于项目原因,需要在嵌入式设备上实现声波通信的接收端。平台是ARM 32bit 500M单核CPU。要求CPU使用率不能太高。音频输入设备是固定增益。产品需求上一次传输大约64byte字节左右的数据,在3~4s内完成,并且达到一个比较高的成功率。
实际的设计主要分为两个层次,物理层和链路层,下面分别叙述两个层:
一.声波物理层
1.音频信道采样率:音频处理使用FFT实现,所以考虑到CPU使用率,本方案使用16KHz 采样16bit的音频。
2.比特数据的调制。
这里先说传输1bit数据的方法,发送端发送频率相邻的两个频率中的一个来分别代表0和1。如图1所示。
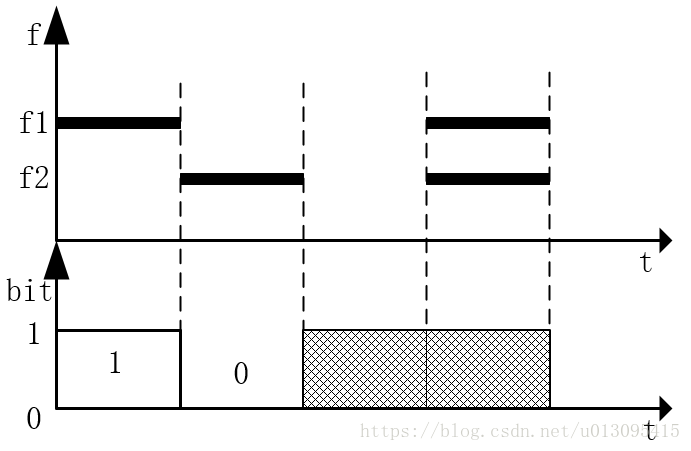 图1
图1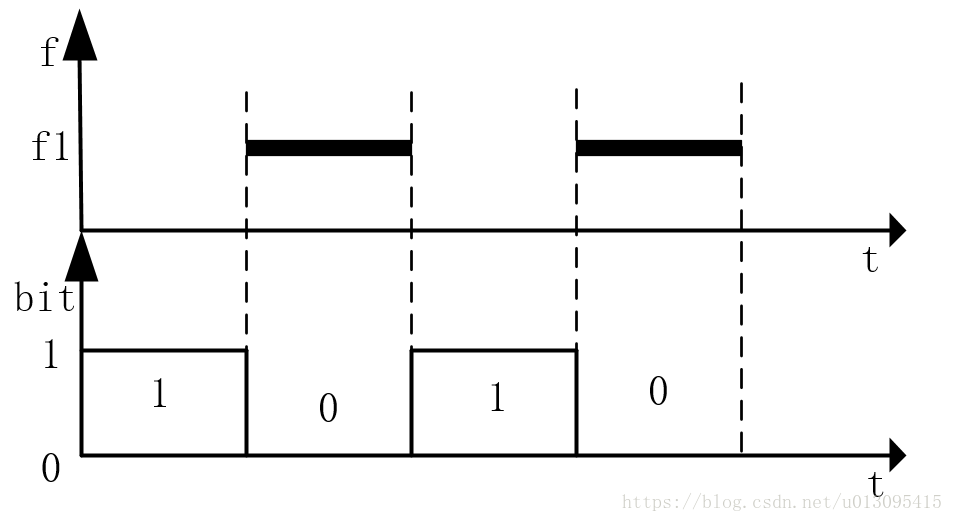 图2
图2
最开始开发时候用的就是这种方法(其实过程中还踩过各种坑,就不一一例举了)相对来说这种方法的优点在于用到的频率点只有一个,但是缺点很严重,在开发过程中发现,实际上接收端不能很准确的判定频率f1的有和无,比如用FFT结果中f1当前振幅A和一个阈值B比较,那么阈值B如果太大在发送端声音较小,或者接收端在该设备上的频率响应较差的情况下会误判;阈值B如果太小容易对噪声进行误判。而最理想的结果就是只能在一个特定的设备上每个频率点调出来一个很好的阈值B,这样就不具有通用性,而且通信的两个设备的距离和音量同样也影响振幅的大小。当然之前还在这个坑里待了挺长时间,甚至想到了前后振幅变化了确定有无,依然失败告终(实际信号有到无的过程中振幅有抖动)。
论述完上述方法之后图1的方法优势就很明显了,接收端只需要比较f1和f2振幅大小就行,比如f1>f2时就是存在频率f1而没有f2。这样在一般情况下,f1和f2衰减都会一起衰减,增大也会一起增大,所以不会受硬件频率响应、传输距离和音量大小的影响;实际上基本原理就是差分传输有效抑制共模干扰。
3.前后帧判断
接收段通过FFT分析一段一段的音频数据,这个应该叫做短时傅里叶变换,即对信号进行加窗分别计算FFT结果。这样就能知道声波在哪段时间拥有那些频率。如图3所示。
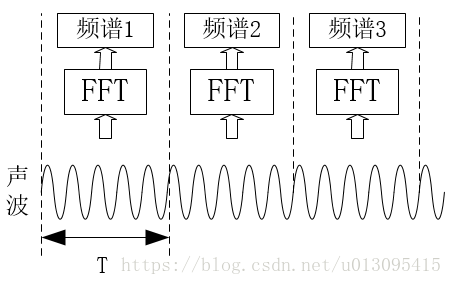
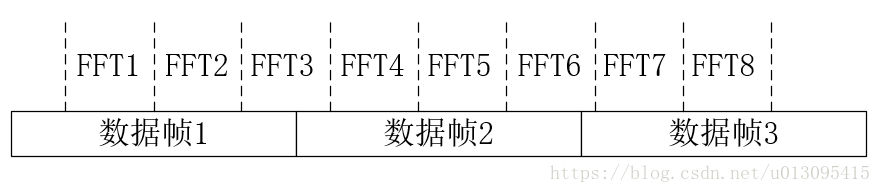
而图4中FFT3的数据中可能会计算出有频率f1或者没有频率f1。所以多个FFT数据中如果发现f1连续出现2~4次认为是发送了一帧数据,同理可以推广到多个的情况,如果FFT计算出来的个数是5~7个,那么真是的数据就是2帧并且两帧数据一样。
4.数据帧长度
由上述可知,由于数据帧的长度是FFT计算窗的3倍,所以数据帧的长度除了会影响到传输时间外,还影响FFT结果中的频率分辨率(由于海森堡测不准原理,如果要想FFT窗口小,频率分辨率就会低。要想频率分辨率高,FFT窗口就得大),并且数据帧长度除以3的采样点个数得是2的整次幂。而且最终一帧传输的不是一个bit而是多个bit(这个下文会说)。综合考虑选取的是24ms一帧。16KHz采样下FFT窗口(8ms)就是128个采样点,对应频率的量化步进就是125Hz,即FFT结果中依次是0、125、250、375、500.....的振幅数据。
5.多频同时传输
前面论述了声波通信的基本原理和相关参数的大小,但是说的是1bit的传输方式,使用上述的方法在不同频率上可以同时传输多个比特。相当于是创建多个传输信道,提高传输速度。
通过实际录制的音频的光谱图可以看出,在1000Hz以下的环境噪声比较大,而由采样定理可以知道,16KHz可以采集的频率在8KHz以下,所以最后选取得到的以下10个传输通道的相邻两个频率点:
通道1:1375Hz、1625Hz
通道2:2000Hz、2250Hz
通道3:2625Hz、2875Hz
通道4:3250Hz、3500Hz
通道5:3875Hz、4125Hz
通道6:4500Hz、4750Hz
通道7:5125Hz、5375Hz
通道8:5750Hz、6000Hz
通道9:6375Hz、6625Hz
通道10:7000Hz、7250Hz
6.奇偶校验纠错
实际开发过程中发现,在声波传输过程中,通常会导致某一个通道内频率衰减(比如距离、遮挡)。甚至会衰减到通道内两个频率振幅大小都无法判断导致数据不对的情况。所以5中所述的10个通道中用一个通道来传输一帧数据(24ms)中其他9个通道的奇偶校验信息,当物理层检验发现数据有错误时(通常认为1个比特位不对),会翻转各个通道中最大振幅最小的哪一个比特,尝试更正错误。因为实际环境中通常都是频带衰减厉害导致数据传输错误,故在声波通信中可以认为发生错误的应该是振幅最小的那一个比特通道。
二.声波链路层
链路层主要是根据应用程序要传输的数据进行RS纠错编码和封包,包括了包头(包含数据大小)、数据、纠错数据三个部分。
1.数据包的结构
上层每4byte数据为一个数据包,最后不足4byte的为一个包。如图5所示:

包头:包头主要用来识别一个数据包的开始,目前定的是0x34,最低两位是用来记录数据的大小(单位:字节)。
数据:即要传输的数据中的四个字节,在数据流末尾如果不足四个字节也封为一个包。
RS纠错位:由于声波的应用场景往往是单向传输,所以不能像TCP通过重传来解决误码的问题,只能由包内包含的信息最大程度上还原错误的数据。由数据段里面的所有数据生成的纠错段,纠错段和数据段总共纠错能力是2byte以下(包含2byte)。
2.数据包的传输方式
发送时链路层数据包由物理层拆分为一帧一帧的数据(由一中的5所述,一帧数据是9bit)来生成波形,接收端也是解析一帧一帧数据由链路层还原成数据包再丢给上层数据。而具体的拆分数据帧的方式有两种,如图6和图7所示:
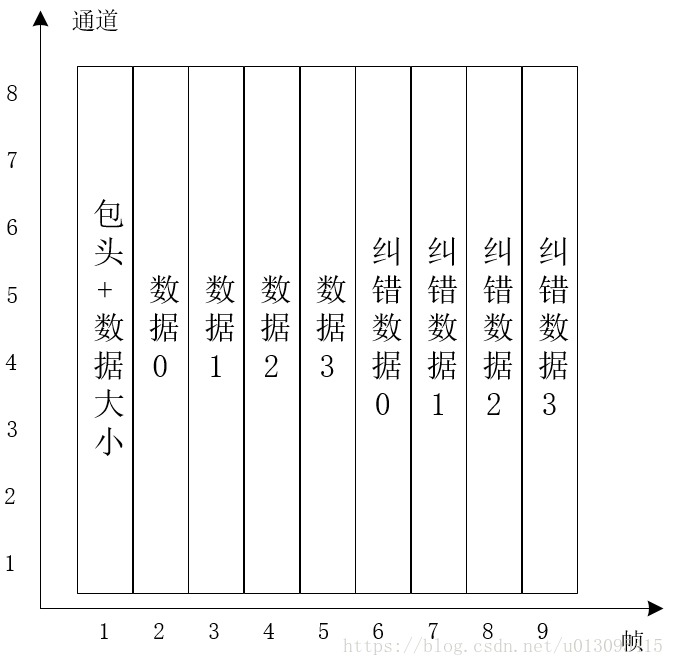

图7
由图可以看出其实就是横着放和竖着放的区别。最终使用的是图7的方式,而图6的方式主要有两个缺点:
缺点1:包头的数据不好确定,同样是8bit,后面的数据段也可能出现和包头一样的数据而误判。当然这个也是可以解决的,我们有9个通道,可以给包头第9bit数据置1来区分头数据和中间的数据。但是这个不是主要缺点。
缺点2:在实际通信过程中,正如一中6所述,往往出现问题都是有一个通道的频带出现验证衰减,导致的误码;那么在图6的方式中有一条通道误码(假设物理层奇偶纠错没有纠正过来),就会导致当前数据包的每一字节部分的数据都可能有1bit的错误。而RS纠错只能纠错2byte。所以在这种情况下RS纠错的意义不大。
在图7的方式中,包头和数据包的其他部分并不在一个通道内,所以很好区分,而且只有1byte。如果有一个通道的频率衰减导致的也是一个字节的错误,这时候RS就能正确的纠正过来。
三.总结
以上叙述了一种声波通信的具体方案,是在实际开发过程中很多次的尝试定下来的一个相对较好的方法,实现了在嵌入式设备场景下的声波通信,对音频硬件模块要求不高,性能消耗较小,目前已经在我当前项目产品中使用。
但是目前该方案还有一些没解决的问题,比如没有解决声波在小空间反射的问题、遮挡比较严重或者扬声器和mic相互背对的情况下成功率较低、声波的音频不太好听的问题(尝试提高采样率和各通道频率效果较好,但是目前项目不支持,所以有需要的可以自行更改或者联系我)。这些问题在之后希望可以得到解决,同时也欢迎大家提出好的方案和建议。
源码地址:
